
I often heard worries in the coffee community about a difference of quality in the coffee grind size distribution when grinding with a full hopper versus a single dose of coffee in an otherwise empty hopper.
The idea behind this is that coffee beans forced through the rotating grinder burrs have no choice but to go through whatever openings they encounter between the burrs. In contrast to this, a single bean in an empty hopper will bounce around and may end up passing through a larger hole between the burrs when the opportunity arises, because nothing is forcing it to pass through very fast. This bouncing around of a bean is what “popcorning” refers to.
As a result of this effect, beans that popcorn will end up getting ground somewhat coarser on average. Grinding a single dose of coffee in an otherwise empty hopper will therefore generate two kinds of coffee grounds: a first batch of slightly finer grounds resulting from beans forced through the burrs, plus a smaller batch of slightly coarser grounds resulting from the last beans that popcorned. The result will be a distribution of coffee particles slightly wider than what you would have obtained if you ground a small dose of coffee with a full hopper.
This more uneven distribution of grinds will cause an increase in the amount of coffee particles larger than average, sometimes called boulders. As I mentioned before on this blog (e.g. see this article), only the surfaces of coffee particles extract efficiently when you brew the coffee, and this larger amount of boulders will limit the amount of coffee compounds that you are able to extract quickly and evenly. Several people therefore suggested that it is best practice to grind with a full hopper, and even to grind one bean at a time if you are extremely patient and want to grind a single dose of coffee at a time.
Now that I built a tool to measure particle size distributions, I decided to test all of these claims. They all make sense, but none of these arguments are really telling us how important this effect is. To do this, I ground 3 different doses of 10 grams each on my Baratza Forté BG grinder. I used the same coffee for all these tests, which is important (especially the roast profile may affect how the coffee shatters). In this particular case, I used a relatively light roast of an Ethiopian Guji by Saint-Henri roasters in Montreal. I ground them on setting 6L with the factory-set zero position. In my case, this means burrs would only touch if I went 3-4 ticks finer than 1A. The first dose was ground with a hopper full of beans, the second one was ground by dropping just 10 grams of coffee beans in an empty hopper, and the third one was ground one bean at a time. This last batch bored me to hell.
I measured the particle distribution of each dose by taking 12 different samples sprayed on a 8.5″ by 11″ sheet of paper and combining them together. I took that many samples to make sure that I would have good statistics to be able to resolve minute differences in particle size distributions. I decided on the number 12 because I noticed that comparing the first 6 data sets combined together looked similar to the last 6 combined together when binning the particle size distributions in 16 distinct particle surfaces, so having double that amount of data seemed conservatively good enough.
As a first test, we can ask ourselves how important the popcorning effect is, i.e. how much coarser do the grounds come out compared to beans forced into the burrs ? To do this, we need to compare the full hopper versus the bean-by-bean doses.
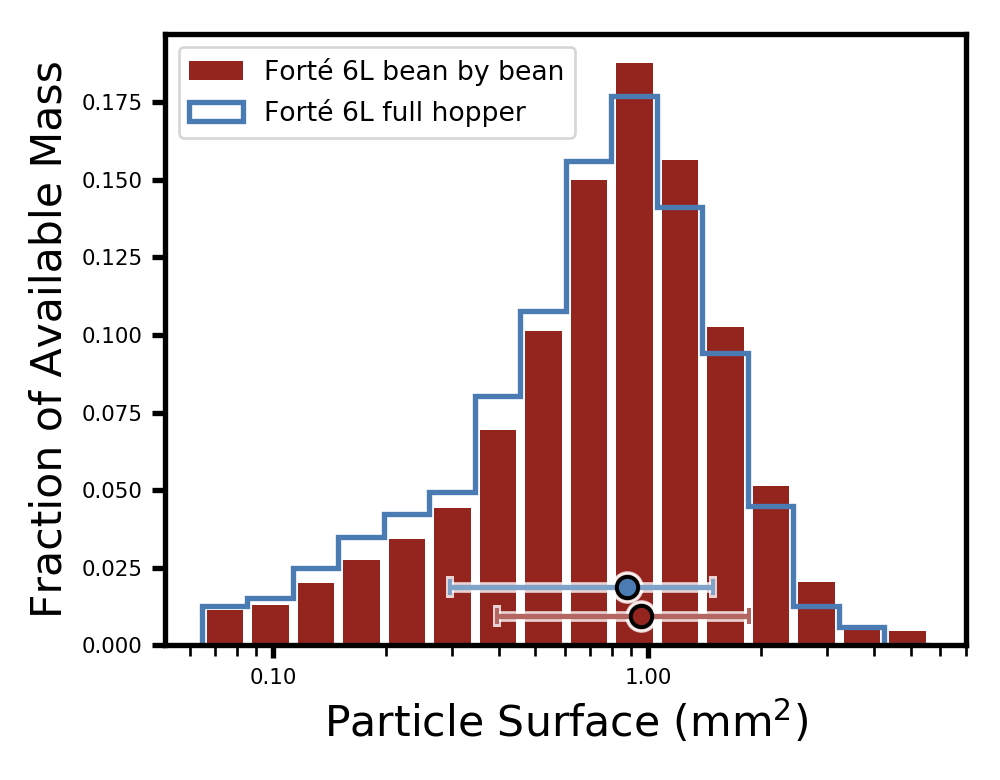
What I call the “fraction of available mass” in this figure is the mass of coffee that is available for extraction if you assume that only outer shells of 100 micron are extracted in each coffee particle. This is just an approximation, but it is already more meaningful than just looking at the total mass of coffee particles. For more information, I suggest reading this previous blog post where I discuss a very interesting experiment carried by Barista Hustle to explain why this approximation makes sense. Basically, we want our particle size distributions to contain some information about how the coffee will extract, so we don’t care about weighing the cores of coffee particles that will never be extracted. I also talked about this more here and here. Another thing to notice in the figure above is that the horizontal axis indicating particle surfaces is in logarithmic scale. This means that every shift of e.g. 60 pixels to the right corresponds to a particle size twice as large. On top of each distribution, there is also a single data point with horizontal error bars, that respectively indicate the average particle surface and the spread of the distribution on each side.
As you can see, we are able to see a difference, albeit a small one: the beans ground one at a time are indeed about 0.08 mm² coarser than those ground with a full hopper. To get a better sense of how coarser they are, I compared the bean-by-bean dose to other full-hopper grind sizes on my Forté, and determined that the closest match was to setting 6Q:
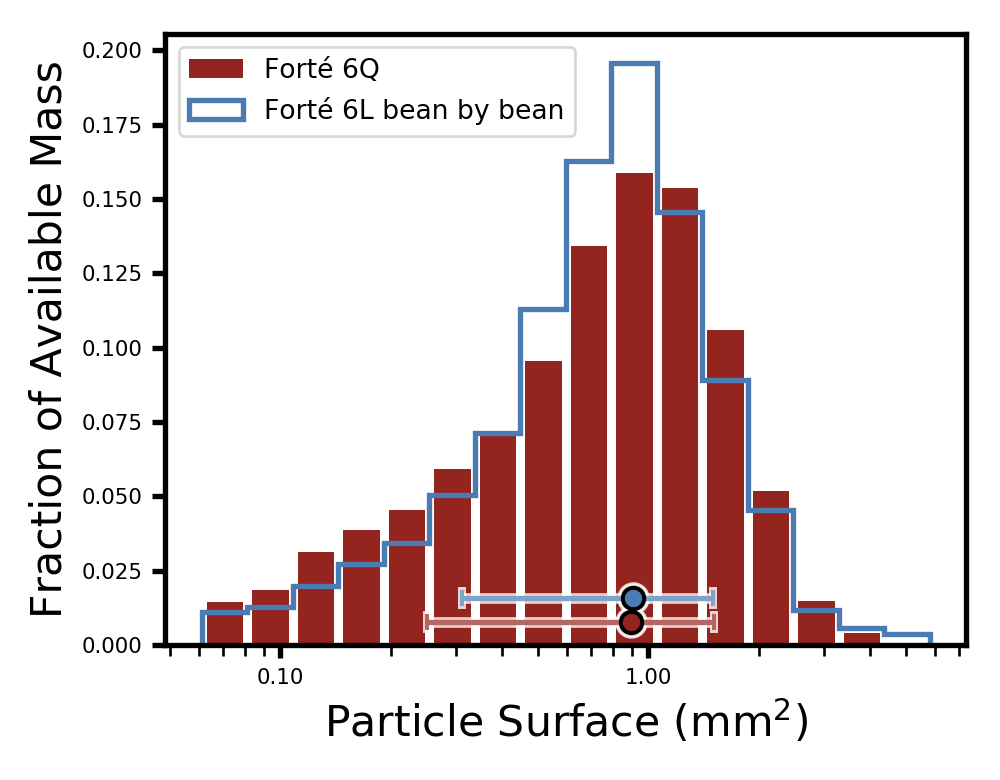
Another interesting part of this is that grinding bean by bean generates a slightly tighter distribution, therefore mimicking a higher quality grinder. It might seem tempting to adopt this practice, but do it once and you’ll see why no one does it. It is also possible that this is just an effect of having started the grinder motor before the first bean hits it; this means the motor was rotating at the same exact speed during the full grind. The “full hopper” and “empty hopper” data sets were taken with coffee already dropped on the burrs before the grinder was started, therefore the start of the dose was grinder at a slower motor speed while it was speeding up. I am under the impression that this doesn’t entirely explain “bean by bean” doing so much better, but I will be isolating out this effect very soon to test that hypothesis 🙂
As we saw, popcorning beans are ground approximately 5 clicks coarser on the Baratza Forté BG. A strategy suggested by Scott Rao to grind a single dose was to start at your desired grind setting, and then change your grind size to something slightly finer when you see that your beans start popcorning. This figure above tells us that, if you wanted to do this, it would be appropriate to grind exactly 5 clicks finer when the beans start popcorning. That may require mastery of the on-the-spot Forté fine controls.
However, let’s first ask ourselves another interesting question; does popcorning affects enough beans to have any effect at all on the particle size distribution of a full 10 grams dose ? The smaller the dose, the bigger the effect will be, as the number of last beans bouncing around will always be the same. To answer this, let’s compare the particle size distributions of the full hopper versus empty hopper doses:
As you can see on this figure, the two distributions are virtually undistinguishable. This means that the popcorning affects such a small fraction of the 10 grams dose that I was not able to see any difference with this analysis. As you can imagine, the effect will be even smaller on typical doses which tend to be around 15 to 25 grams. As we saw previously, the last few popcorning beans were clearly affected and they were ground coarser, so there has to be a difference between the two particle size distributions even though it is a very small one. But to put this in perspective, the overall difference on a 10 grams dose has to be much smaller than one click on the Forté, and also much smaller than the difference in grind quality between all different brands of grinders I have ever tested. This includes Comandante’s C40, Orphan Espresso’s Lido 3, Mahlkonig’s EK43, Lyn Weber’s EG-1 and Baratza’s Forté BG. All of these grinders generate particle distributions that a similar analysis can easily distinguish.
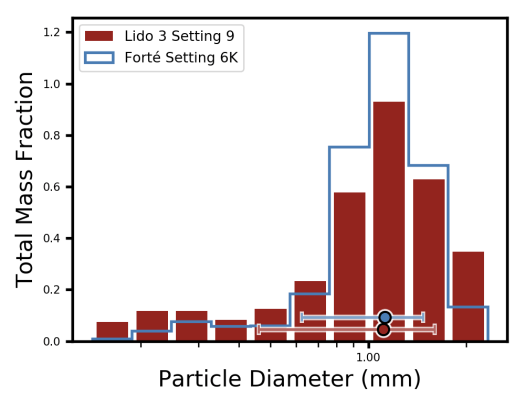
The take out message that I got from this experiment is that popcorning has a non-negligible effect on grind size, but it affects a negligible amount of beans in any reasonable dose of coffee. You should therefore not be afraid to grind single doses at a time, because any degradation that results in your particle size distribution will be much smaller than any difference between brands of grinders. I’m hoping this post will alleviate the admittedly first-world and very geeky problem of single-dosing anxiety.
For those geek enough to ask or even to make it this far in the post, I did make my data public on Github.
I’d like to thank Douglas Weber for useful comments, and Victor Malherbe for proofreading.

Very interesting post Jonathan, thank you 🙂
LikeLiked by 1 person
Hi Jonathan, thanks for all your hard work.
I wasn’t sure if you also tested Burr size, or hopper size, and if it will make a significant difference in these results?
Also, do you think Burr RPM will make a difference?
Thanks
LikeLike
Hey Craig, thanks. I did not test any of these, only used the 54 mm burr that comes with my Forté BG, and the hopper that comes with it. I would be surprised if any of these make a difference – the relevant phenomenon here is having a force that pushes beans through the burrs or not. Chute design could have an effect, but the main takeaway that pop corning just happens on a very small amount of beans should also not depend on any of these things, meaning that single dosing is probably not an issue for > 10 grams doses on any grinder.
LikeLike
Reblogged this on Quaffee and commented:
Taking the witchcraft of coffee grinding closer to science.
LikeLike
Oh man .. just started to read through your other articles, and I am so thankfull to James Hoffmann for mentioning your analysis software and thus directed me here 🙂 I just love the detail and depth you go into every time, and at the same time, I feel much more sane and normal about my experiments – though by no means as scientific and precise as yours … You also definitely saved me loads of time 🙂 (which I will use to prepare your siphon high extraction recipe today … sounds to be really great idea ….and also another use for my melodrip 😀 lol … btw .. have you noticed the steepshot on KS? seems like it can be of some interest for this style of brewing too )
LikeLiked by 1 person
Thanks ! I haven’t what is it ?
LikeLike
One thing that bothers me though – since I do not have a scientific background and have not been exposed to log scales in data much, I find it hard to intuitively understand what I see – I understand how the scale works, but I feel like I interpret the shape of the diagram wrong because of the log scale …. Is there something you can recomment to get better intuition about what this log scale graphs actually mean? I stayed linear in my measurement plots exactly because I felt like the its easier to understand for me ,,,, though I see everyone is doing the plots in logarithmic
LikeLike
Plots in log just condense the information more. Basically as you shift right the “zooming out” on larger particles accelerates. Often in nature log scales show simpler relations because a lot of things tend to be power laws (straight line in log), log-normals (normal distribution in log), etc. It’s just a stretching of the linear plot (some bars get combined along the way)
LikeLike
The steepshot is a relatively simple brewing device (though supported by Tim Wendelboe :)) so … I have high hopes) … you can check on kickstarter, as they are still to finish the production and deliver. Whats interesting maybe for you, is that it uses the pressure buildup from hot water inside of the brew vessel to push whater out fast after the brewing is done (kind of opposite to what siphon does), and brewing under (some) pressure before its released in the end. So the basic aplication of it makes the brewing faster and pushing the coffee out through filter too .. i guess going fine with the grounds, maybe changing the metal filter or adding paper to it, and it might be possible to do a simillar process like with the siphon 🙂 maybe even enhanced by the pressure.
LikeLike
It’s not really popcorning that’s hapenning here imho, it’s the fact that the first few grams of a single dose are ground like intended ie. With some backforce behind them, the burr chamber is full, so bean / bean fragments behave differently to when there are free to move about. Bean fragments get fed down the burr cuts and gradually get smaller, the last few beans can’t benefit from this, which for some reason generates coarser particles or simply less fines / more shards?
Also, I wouldn’t say 10g is a good test sample size, you will see less of an effect as 10g barely fills the burr chamber. Go with 15-20g and I’m sure there will be a bigger difference between start and finish.
Also, it would be worthwhile comparing the distribution of the first 2-3g from a single dose to the last 2-3g, but again you need a larger dose size to see a bigger difference.
Lastly, have you checked your distribution tool against results from some other distribution analysis method? I’m simply curious how thrustworthy it is as it’s not easy to test distribution especially on espresso grind level (fine particles clinging to larger ones). Brew size level is a different story, but there I think bean by bean has less of an effect as overall particles are much larger.
The easiest test which shows how single dosing is different from bean-by-bean is pulling espresso shots. Dial your grinder to give you a reasonable espresso shot and then pull another one but bean by bean dose the grinder. It will be a gusher and you will have to go way finer to get a reasonable pour. On a conic this means moving from 0.60mm burr gap to 0.45mm burr gap, in espresso this would normally move you from a normal flowing shot to a complete stall.
I’m not saying bean by bean is better, but there is a difference which can be easily tested on real equipment doing real brews. It also produces higher EY, at least on my kit. It’s a ball ache don’t get me wrong, but it was an eye opener on how burrs work.
Regards,
Tom
LikeLike
Hi Tom, yes clearly the lack of force pushing beans through the burrs is the important point here, I agree with this, and this is what I tried to convey in the post. The only way I can think of that particles end up coarser in a situation where nothing is pushing them through the burrs is simply that they have more “choice” of rebounding versus passing through a larger aperture at any given time, whereas beans that are forced through have to pass regardless of the aperture size. In my view, this means that popcorning is literally the important aspect, or if you really want to be picky, popcorning & coarser grind are both consequences of the same effect: the lack of force pushing beans through the burrs. I already replied to the dose size part on Instagram, so I’ll just copy paste that part here: “One the dose size however, here I disagree completely. The reason why single-dosing would produce a different distribution to start with is the fact that the last few beans aren’t forced through the burrs. If you use a larger dose, the same amount of beans will be “not pushed through” at the end, but they will be diluted in a larger dose. Therefore, the smaller the dose, the more different you would expect a “full hopper” vs “empty hopper” distributions to be.”
Regarding the comparison of the first to last 2-3 g in a single dose, here’s my prediction: the first 2-3g will have a distribution extremely similar to the “full hopper” scenario, and the last 2-3 g will probably be similar to the “bean by bean” scenario, although we might need to even look at a smaller portion (maybe the last 0.5-1 grams) to see this. I don’t think I’ll spend the required ~2 hours to do these measurements properly, but you will be able to do it yourself soon once I release the option to merge CSV files together. Taking about 12 samples per distribution is needed for precision, and you can have a look at the GitHub files to compare your data collection and make sure you have no clumps of particles in your pictures.
About the espresso shots: I may be misunderstanding you, but I think we just plainly agree there. My experiment shows a stark different between “bean by bean” and “single dose”, so it is no surprise to me that the espresso shots will be super different.
The fact that “bean by bean” produces higher EYs is also consistent with what I find above; the bean by bean distribution is a bit narrower (assuming you dial it in differently to get a similar grind size), so it should allow you to obtain good-tasting higher-EY shots, yes.
LikeLike
Hi Jonathan,
Quick recap just to clarify a few bits as I think I’ve made some assumptions which don’t neccessarily hold true.
Popcorning term-wise – as I said on Instagram, to me and most likely a lot of people popcorning = beans bouncing around. The gradual coarsening of a single dose isn’t imho caused by this, it’s due to lack of load / backforce pushing the beans down. Popcorning aka bouncing, happens due to lack of load though, but it doesn’t cause your grind to coarsen near the end of the dose.
Dose size – indeed a smaller dose is closer to an empty hopper kind of scenario. The assumption I made was based on the idea that you are testing the first few grams with the last few grams of a single dose, which of course isn’t the case. I’d still argue that it would be best to use a dose which is typically used for filter/spro, so 18g for example would make sense. Don’t think anyone uses 10g so results taken from testing on a such a small dose won’t really apply in real life scenarios.
Own testing – would love to, but I don’t think photo base grind analysis is going to work so well for espresso grind level simply due to super fine particle clinging on to larger ones. I think LPA is rather inefficient with espresso grind size, same goes for sifting as fines tend to clog sieves and I don’t know a method that works well. I will however try it out as I’m very curious what the results are going to be.
I mentioned espresso shots simply to highlight how easy it is to see a difference and the fact that it is a big difference. Doing this testing on a filter grind isn’t really ideal imho simply because the particles are so big and the difference between full hopper and single dose is small, I can see however why it’s easier to test it like this (see comments on own testing above). I’d still recommend doing the split cup method where you prep 3 doses of say 15g, run your grinder, drop the first dose in, do a short burst to get 5g out into cup no 1, then do another burst to get 5g into cup no 2 and last burst to get 5g into cup no 3. Repeat for the other 2 doses and then do particle analysis on cups no 1, 2, 3 (or just pull shots with them).
Regards,
Tom
LikeLike
Hey Tom,
Term-wise: I totally agree; both are just consequences of the lack of force. It’s widely referred to as the “popcorning” effect though so I won’t re-baptize it.
Dose size: My idea was rather to do a very small dose and hopefully detect the effect. What I did shows that, for filter grind, no realistic dose will be affected by single-dosing.
Espresso: It’s true that it will be harder for espresso because of fines sticking. However, relative differences might still become apparent if the amount of static doesn’t vary too much. The reason I didn’t test for espresso is mainly because I’m not too interested in the matter; I almost never drink espresso. Hence I didn’t think much about it, but my experiment definitely can’t be taken as conclusive for espresso.
LikeLike
Thanks to the author for writing like this deeply informative article. It’s very helpful for others who want to know the grind quality like me.
LikeLike
Hi J
I really appreciate your passionate work, it has helped me alot in my quest for a perfect coffee. I am drinking espresso and have a flow profiling machine and I struggle picking up a grinder that gives me an EK style of espresso but without the immense pain in the ass of a grinder the EK43 is.
I recently realized that having a profiling capable machine I need a very unimodal grinder because at low flow and lots of preinfusion I struggle to get really good espresso.
For home users I cannot imagine using a hopper grinder as the waste and the stallness of the grinds retains by 90% of the grinders kills the home barista experience, especially if you are obsessed about quality, as most of use interracting with you are. So, I only single dose at home on various coffee shop grinders, modified so I get minimal retention.
I wrote you those lines so that I stand my point of view in regarding this matter of coffee going through burrs, as single dosing users know from experience how the grind is effected by the lack of a hopper. My only logical explanation of the grind difference is that the difference in grind sizes of he first few and last few grams are because beans forced down by the burrs collide and brake while waiting in turn for the last bit of the burrs to grind them, thus creating more finer particles in respect to the last few grams that have all the space in the world and no force making them crush against eachother.
The theory of the beans finding larger spaces between the burrs does not seem exact because the space between the burrs is equal, so even if that bean finds itself a larger path to be ground, it will still have the same grind size, as the burrs have a consant distance between them, thus grinding all the same.
I could be worng by this is what i imagine is happening and thats why hopper used grinders need coarser grinding.
I used the following grinders: Ceado E5P, Mahlkonig K30, DC One, NS Mythos, Robur, all espresso grinders, incapable of letting me have a decent Chemex pour without stalling due to fines, but the blame is on the burrs because i used all of them single dosed.
How do you compare the Forte to the EG1? Have you had any experience with an EK43?
Sorry for my long message, I hope I made myself clear enough.
Thank you!
LikeLike
Hey, all I can say is that for filter grind size with the Forté, single dosing made no difference at all for > 10 g doses.
The hypothesis is not that the distance between burrs change. The burrs are not flat surfaces; they have teeth which means that the openings that you would see if you were a coffee particle at the center of the burrs and stared outside change in aperture as the burrs rotate. If they rotate very slowly, sometimes these apertures are larger (valleys between burr teeth coincide), and a slightly larger coffee particle could escape uncrushed during this alignment. If the burrs turn extremely fast, no particle would have time to pass during one of these valleys alignment, and therefore there would be less boulders.
I have tasted about twenty brews made with well-aligned EKs (Titus-aligned burrs and carriers). They were brewed by Andy from Tunnel Espresso, myself or Scott Rao and they were generally great except those where we were experimenting. The EK burrs were stock burrs on the old EK models for about half of tbe brews and SSP low-fines burrs for the rest. The EG-1 is certainly in the same ballpark than EG-1 if I compare taste; Scott has made some higher-EY V60s than I have but I’m not sure if that was the grinder or his technique. Taste wise I can’t say which was better (I only compared them next to each other with one brew while dialing in & seasoning the EG1 and using an approximate grind size on the EK and both Andy and I preferred the EG1 brew, not sure that one data point means much however).
Looking at the grind size distribution of grounds that Andy sent me from his EK, the EG1 (also SSP ultra low fines) was slightly more uniform than EK, but not by a very large margin. My experience with the EG1 so far has been extremely positive; it’s a whole different world than the Forté.
LikeLike
Sure, but the outer edges of the burrs have the same distance, so that is the final crusher of the beans before throwing them out, the single variance can be of the smaller particles which are affected but the beans being crowded while being ground, am I mising something?
I just love the looks of the EG, I cannot get over the price though, it is just too much for me to bear psychologically, even though I was willing to spend that amount on the espresso machine 🙂
LikeLike
What matters is the distance between the surfaces of the two burrs. That distance changes during burr rotation, as the teeth pass through each other. Therefore, for a fixed coffee exit speed, faster rotations means a coffee particle has less chances of slipping through between teeth, therefore fast rotation = finer on average. I’m not sure how to spell this out differently.
Yeah the EG1 is quite expensive I know. I don’t own an espresso machine so that made it easier 😛
LikeLike
Do you think it would have been worthwhile to test dropping a ten gram dose in an empty hopper with the grinder already running/burrs fully up to speed? This is a common practice in cafes.
LikeLike
Hi Jackson, yes, this is precisely what the “empty hopper” case corresponds to.
LikeLike
Great experiment and write-up. Thanks for this
LikeLike
Hi Jonathan, not exactly on topic but more on your practical experience with the Baratza Forte. Were you ever single dosing? If so, did you have any issues with it and/or switching between different beans?
LikeLike
I was almost only single dosing with my Forté. I found it a bit awkward to use it for single dosing but didn’t really have major issues. It had a bit more retention that I’d like (probably 3-4 grams but I haven’t measured precisely).
LikeLike
Hi, I’ve been playing with the analysis software today and it’s amazing. Thanks so much for producing this. I was wondering if you’ve seen data being shared anywhere in .csv format to load as a comparison into your software? Or whether you have any data from some of the higher end grinders to for comparison? Thanks
LikeLike
My background is more of a mechanical nature. I believe when there’s only a few beans entering the bur and receiving their 1st crack they exert enough force that opens the bur on that side of the bur allowing grindings that are courseer to escape. If this is happening around the circumference the load is distributed evenly i.e. full hopper.
LikeLike
Great post! I didn’t know anything about the popcorn effect. Interesting a thorough research work. Congrats!
LikeLike