
The picture above sent by my friend Francisco Quijano is an awesome demonstration of how different a V60 (left) and Aeropress (right) brews of the same coffee may look like.
I’d like to talk about why coffee brewed by immersion (e.g. french press, Aeropress, siphon) tastes so much different, and even look so different, than coffee prepared by percolation (e.g. pour over or drip). Some of you may have noticed that this holds even when you compare them at similar extraction yields and concentrations.
In a previous post, I talked about a more general equation for extraction yield that should provide a better correlation with the chemical profile of a coffee cup, and therefore with its taste profile. Obviously, it doesn’t capture effects like changing coffee, roast curve, or even grind size. But there’s something else fundamental that the general equation cannot capture, because the taste profiles generated by immersion and percolation brews just live in different landscapes. Today I want to explore why that is.
The crucial difference between a percolation and an immersion is simple: a percolation extracts coffee with clean water, and an immersion extracts coffee with water that is gradually becoming more and more concentrated, because water sits in with the coffee grounds for the whole brew.
Because of this, the speed of extraction levels off more quickly in an immersion brew. This arises from the physics of diffusion; any solvent more concentrated in a specific chemical compound will have a much harder time extracting that same compound from the coffee grounds. This concept is described by the Noyes-Whitney equation:

You can read more about the different terms of this equation here, but basically this just tells you that the rate at which a compound gets extracted is higher when the solution is much less concentrated in it than the coffee particle.
So far, it would seem like this only explains why an immersion would extract slower, not why it would extract a different profile of chemical compounds. But there’s a catch: even if water is concentrated in a specific compound, it doesn’t prevent it from extracting other compounds efficiently. Therefore, if you wait long enough, an immersion brew will very closely reflect the chemical composition that was initially in the coffee bean, as each individual chemical compound comes to balance with the slurry. If you stop the brew before everything is extracted (which we usually do), the slowest-extracting compounds will be a little bit underrepresented, but otherwise the chemical composition of your cup will be a pretty good reflection of the chemical composition in the coffee bean.
In a percolation brew, things happen very differently. This is true because at every moment, the slurry water is replaced with cleaner water, therefore forcing the extraction speed to remain high as long as it’s not depleted from the coffee bean. As you might deduce, this means that the fast-extracting compounds will be over-represented in a percolation brew.
In other words, the chemical profile of a percolation brew will be very strongly correlated with their extraction speed, whereas an immersion brew will be instead strongly correlated with how abundant each chemical compound is in the coffee bean. It’s like listening to music with two different equalizers on.
I like explanations with words, but I like figures even more. We can explore the difference between percolation and immersion brews by simulating two different brews with a very simple toy model, based on solving the Noyes-Whitney equation numerically. In the percolation case, the slurry concentration term will always be forced to zero as we constantly replace the slurry with fresh water.
Let’s imagine we have a coffee bean with 30 different chemical compounds; and put them in a coffee bean with different abundances and different extraction speeds. I generated 30 such chemical compounds at random, and obtained this distribution:
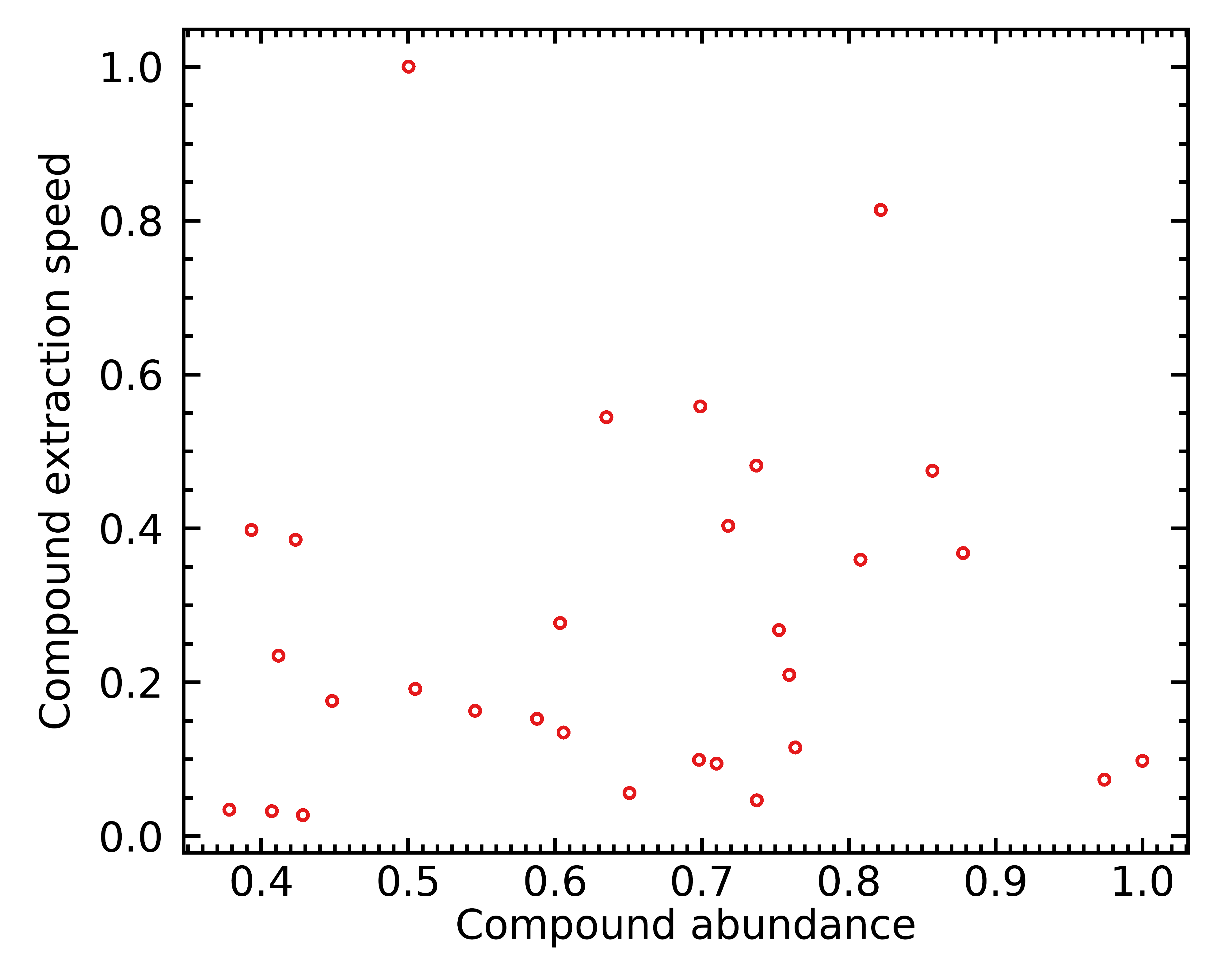
Each red circle here is one of 30 simulated chemical compounds. Those further to the right are present in larger quantities, and those further up are easier to extract.
Now, let’s solve the Noyes-Whitney equation for one of them. Here’s how the brew concentration goes up over time for the fastest-extracting compound:

This should be nothing surprising: the extraction speed levels off much earlier during the immersion brew, because the slurry water becomes too concentrated. In the percolation brew, the extraction is still happening for as long as the chemical isn’t depleted from the coffee particles.
Now, we want to compare these two beverages at the same extraction yield. To do this, I generated the extraction of all 30 compounds simultaneously, and stopped the brew when the average extraction yield reached 20.0%. I made the assumption that the chemical compounds that can be extracted from the bean amount for 28.0% of its mass. Unsurprisingly, the immersion brew took a bit more time to reach that average extraction yield.
Something really fun we can do with this simulation is look at the profile of chemicals in the final cup for the immersion versus percolation, and compare it with the chemical abundances in the coffee bean. This is what we get:

Each bar in this figure represents one of the 30 chemical compounds we generated randomly. I placed them in order of extraction speed; those further to the right extract faster.
One thing that immediately jumps is how the immersion brew (red) is much more similar to the internal coffee composition (black) compared to the percolation brew (blue). The only difference lies in the compounds that are slowest at extracting, as expected. If we let the immersion brew continue, this difference would become smaller and smaller, and eventually subside completely.
The percolation brew looks quite dramatically different from the internal composition of the coffee bean ! As you can see, those compounds that extract fast become completely over-represented compared to the internal coffee composition.
As it’s already quite clear from the figure above, an immersion brew composition correlates mostly with the abundance of chemicals inside the coffee bean:
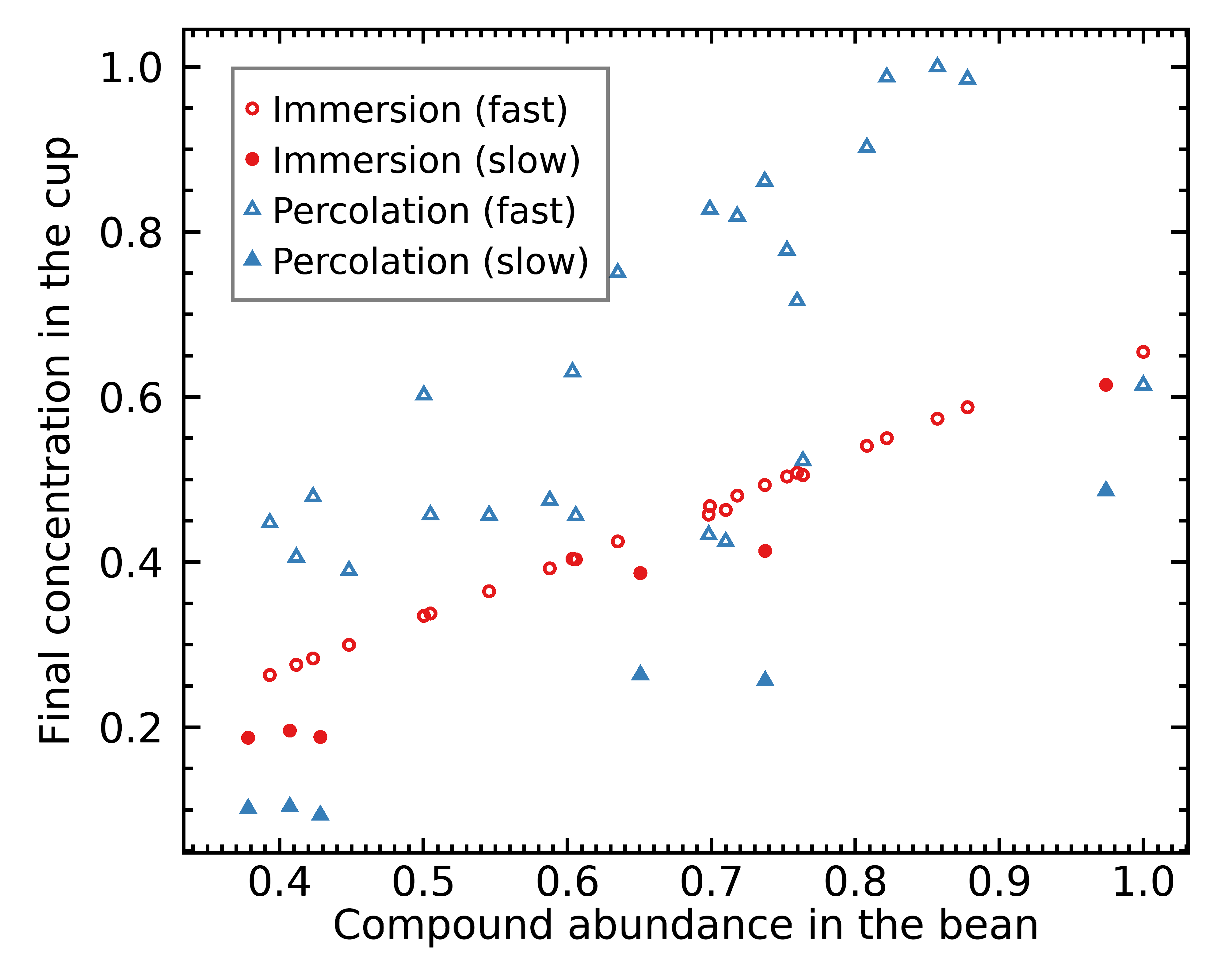
This correlation is quite strong as you can see, with the exception of the 6 slowest compounds that are still out of balance because we stopped the brew before an average extraction yield of 28.0%.
Here’s another interesting observation: a percolation brew correlates strongly with how fast each chemical compound can extract:
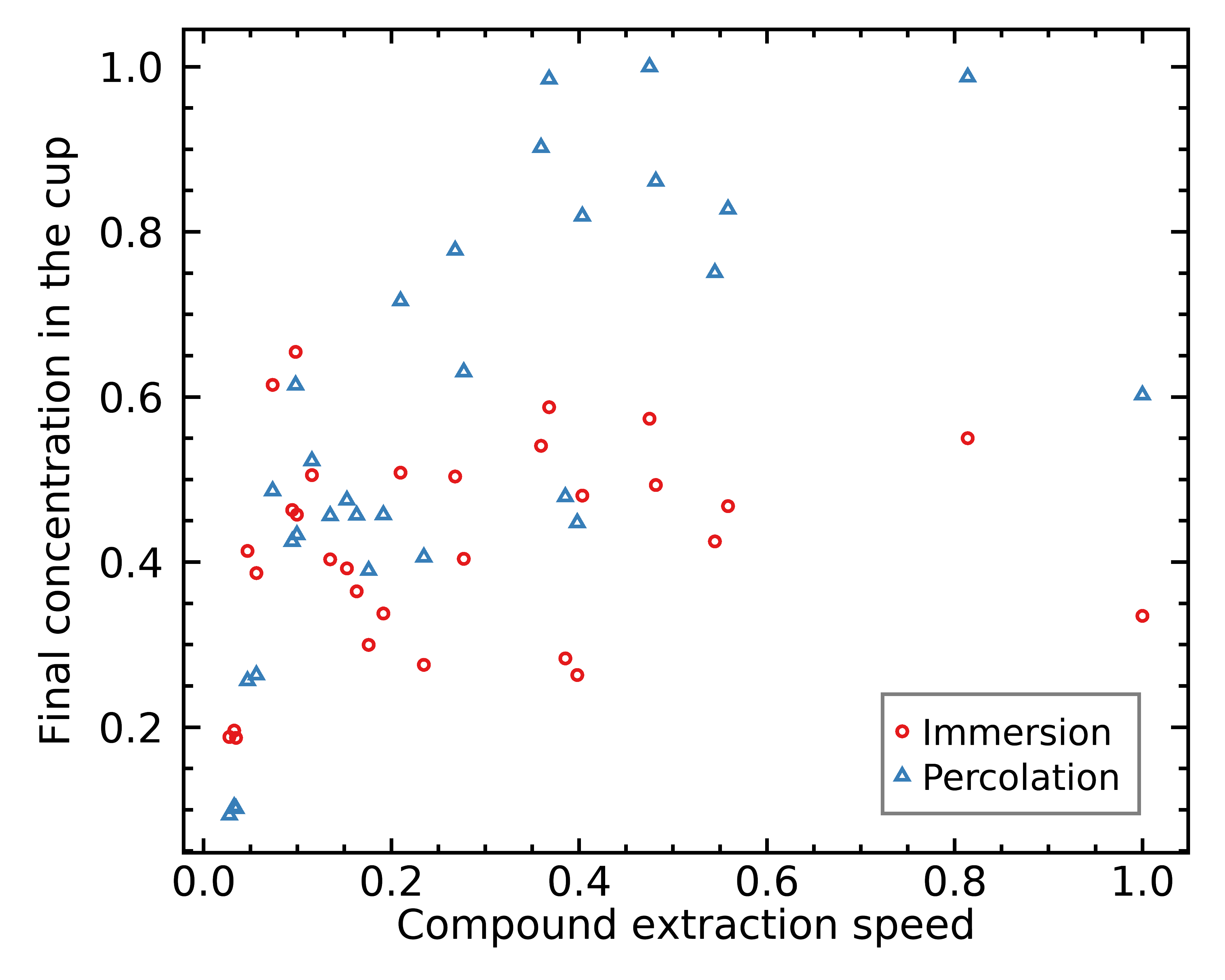
As you can see above, the compounds further to the right are much more represented in the cup of percolation coffee, whereas they are not necessarily over-represented in the cup of immersion coffee.
All of these considerations only hold true because we stop the brew before the maximum theoretical extraction ceiling. If we were to extract everything from the coffee beans, then obviously the immersion and percolation brews would end up with the exact same chemical profiles, the brew times would just be different, and the concentrations would also be different if you used different quantities of brew water. To demonstrate this, I let the simulation run all the way to 28.0% and made a video of how the flavor profiles extract. You can see that, although the beverages converge to different concentrations, they both end up with the same profile than the coffee bean composition:
Obviously, there are other complicating factors that can make different types of brew even more different. For example, the presence of channeling in a percolation brew can bring out a lot more of the slow-extracting (usually astringent) compounds from a small fraction of the coffee particles, which as far as I know never happens in an immersion brew. But if you make sure to minimize channels in your coffee (I give some tricks on how to do that in my V60 recipe and pour over video), this won’t be a significant effect.
Another potential difference is suspended solids. Those are almost always filtered out by the bed of coffee itself in a percolation brew, whereas they will remain in your cup in simpler immersion brew methods like the french press. These compounds can have a strong effect on taste (usually muting it), even if they are not dissolved in water.
I’m sure some of you were surprised when I listed the siphon and Aeropress as examples of immersion brews at the start of this post. I know they are mixed methods, but in practice their tastes bear more resemblance to an immersion. I suspect that the reason for that is simply that most of the extraction happens during the initial immersion phase, not during the subsequent percolation phase. But surely, their chemical profile probably looks like some average of the percolation and immersion profiles.
You might think that this whole post is defeating the usefulness of the general extraction yield equation I mentioned before, but I don’t think it is. I will need a mass spectrometer to prove it, but I think that (1) for a fixed coffee and method, it will make the extraction yield measurement depend less on the amount of retained water; and (2) for different brew methods, it will make the comparison a little bit better, even if it’s never perfect. The comparison will certainly be made much better for two different methods in the same category, e.g. a Buchner percolation (without immersion phase) and a V60.
Before closing, I’d like to add a caveat to the analysis above; what I carried here is a simulation of random chemical compounds that don’t necessarily exist, just to demonstrate the concept of how extraction happens differently in immersion versus percolation. It is a dimension-less analysis (i.e. it does not involve any physical units), and therefore it does not indicate how significant these differences between percolation and immersion are. I do not know whether they are the cause for 1% or 50% of the taste difference between percolation and immersion (the rest of the difference would be colloids, fines, etc.), but my guess is that it is much less than 50%. One way to test this would be to perform blind test comparisons of a Hario immersion switch and V60 brews, but keeping all other variables constant will be a real challenge – just think of how the slurry temperature evolves during the brew in both cases; depending on the kettle temperature, constantly changing the brew water versus keeping the same water in an immersion will have a significant effect on the temperature profile, unless extreme caution and precise instruments are used !
I’d like to thank Francisco Quijano for sending me his awesome photo that serves as this blog post’s header, and Matt Perger for useful comments. I’d like to thank Aurelien He for proofreading comments.

Amazing post ! Today I understand even better why the Immersion want finer grind than Percolation.In what I would like more clarity (poor English) is where you talk about different amounts of water and where you are talking about different temperatures. I’m not sure if I understand these two points. Thanks
LikeLike
Different temperatures would also cause different flavor profiles, so doing an experiment to taste the effect if immersion vs percolation would require a very careful temperature control
LikeLike
I just mean that different brewers create different insulations and therefore different temperatures versus time. For example, Aeropress is extremely insulating and will keep a temperature more stable than a V60.
I talk about different amount of water just because reaching the same EY in an experiment may require different amounts of brew water in percolation vs immersion.
LikeLike
Does it mean that the Immersion will want more water using the same grinding?
LikeLike
I’m not sure which one will require more water, we’d need to test
LikeLike
I know in percolation we’re losing a lot of temperature, but on SOME Immersion not (aeropress). That you mean? Also, when talking about different amounts of water , can you explain to me?
LikeLike
Nice challenge! Thank you for your clarifications
LikeLike
Do you have any further reading on (or would you mind explaining) how different molecules can keep dissolving efficiently even if water is concentrated in some compound? For instance, I would have thought that if a diffusion layer is full of molecule A, then molecule B would have trouble passing into a bulk solution because there is less space in the diffusion layer for it to move through.
LikeLike
Not from the top of my head, but I’ll look for one. My suspicion is that documentation on the chemistry of exchange resins might help (they use this concept)
LikeLiked by 1 person
I haven’t yet found a great read about it, despite searching for one. All I’ve found so far are very technical articles which are probably not too helpful. I should add a caveat that this concept is true only when no chemical reactions take place between the diffusing compounds. When that happens, instead of having one independent Noyes-Whitney equation for each species (as above), you end up with a series of intertwined equations (in the context of stellar atmospheres these equations are called the Saha equations, but I think that name is reserved specifically for ionised – i.e. really hot – gas).
LikeLike
Hi Jonathan, If we make two coffees, an Immersion and a Percolation and get the maximum extraction for both eg 30%, would taste the same if the coffee has nothing else to give? I do not know if I’m clear
LikeLike
Thanks for checking, anyway. I think I figured it out.
LikeLike
How have you deduced that they taste different, beyond differences in filtration & stratified concentration in a percolation? Surely, you need to keep all factors the same (brewer, filter, dose, beverage size, concentration & repeatability), which will ultimately possibly mean having to change something about the way you brew one, or both?
And shouldn’t this comparison have been done first, establishing the difference is significant above the noise of similar brews, before posting?
I’m not saying there isn’t any difference, but I doubt it is very noticeable once you have eliminated the malfunctions of the least preferred brew.
LikeLike
Hey Mark, I have not deduced that they taste different beyong filtration etc. I’m not saying this is the definite cause for taste differences and not fines etc. (in fact there’s a paragraph in the post that already says that, the effect could be tiny or detectable, I don’t know). This post is an explanation of how diffusion works differently in the two cases, and how this could play a role in the different tastes and colors. The toy model is meant to illustrate these differences. Doing a quantitative experiment will be a whole different thing, and will require a spectrometer because it’s extremely hard to get objective measures of tasting.
LikeLike
Hi Jonathan, when you suggest that the different methods might taste different, I think people expect that difference to be detectable on the human palate – even though I’ll be first in the queue to see the spectrometer results 🙂
LikeLike
Oh yeah sure, but if there’s no difference in a spectrometer there shouldn’t be a difference in taste. However the way we taste things might be a highly nonlinear response to the composition, I just find chemical composition much easier to deal with numerically. At least we could say stuff like “there’s more malic acid” and that would give us indications of how the taste is probably affected.
LikeLiked by 1 person
Very nice post! Plus it would be revolutionary to replace your random chemical compounds with real ones at some point in the future.
What do you think about cupping? Everybody enjoys the coffee on that process. Maybe it’s a matter of perception and good mood, I am not sure. But maybe it has something to do with the steeping time or the declining temperature profile.
PS: it’s really disappointing that the methods that have far less channeling (immersion) never taste that good
LikeLike
Thanks ! Yeah I’d love to do that with real data, it would require real expensive equipment though 😛
I like cupping too. The only downside for me is the grounds floating in there, but the combination of high EY without channeling is great. I think the concentration is also a bit too low for what I like to drink every day, but it’s a great diagnostic tool.
Yeah agreed, the problem is that the only practical way to really remove all suspended solids is filtration with the coffee bed itself. Perger used to compete with fritted glass Buchner with allows to do this with no risk of channeling, but it needs to be cleaned with sulphuric acid. I’ve wondered if silicate filtration would be doable, but it’s probably very expensive and wasteful.
LikeLike
Well, buchner funnel sure looks interesting, no argues on that
LikeLike
Hi Jonathan! If we make two coffees, an Immersion and a Percolation and get the maximum extraction for both eg 30%, would taste the same if the coffee has nothing else to give? I do not know if I’m clear
LikeLike
Yes, at the extreme of 100% available compounds extracted, both chemical profiles would be the same exactly. However suspended solids in the immersion brew might still make it taste different (unless it’s filtered). There’s also a big chance that you needed more water to extract everything by immersion, so your beverage would be less concentrated.
LikeLike
Because you have rewritten me that it may take more water for the Immersion, what you mean? In conditions where all the parameters (temperature, grinding, etc.) are the same? Can you clarify ? Thanks
LikeLike
Yes, with everything else fixed you need more water for an immersion because it extracts slower
LikeLike
More water in an immersion, assuming brewing at typical ratios from 1:18 to 1:15, doesn’t make much difference. Because declining temperature immersions are slower, they need more time, or better insulation, much more than they need increased water. Given the required time & heat retention TDS is comparable to drip.
LikeLike
Sure, I meant with everything else fixes (including temperature and brew time) an immersion would need more water for the same EY
LikeLike
This is great! What a neat idea to apply Noyes-Whitney to coffee extraction.
1. So I guess you divided the mass of the dissolved coffee compound m by the volume V of the slurry to obtain the slurry concentration Cslurry, in order to rewrite the Noyes-Whitney equation as the ODE:
dCslurry/dt = A . D/d (Ccoffee – Cslurry),
which you then solved numerically in Python?
2. However, assuming that Cslurry in a percolation brew is nearly zero (that is, Ccoffee >> Cslurry), the above equation reduces to:
dCslurry/dt = A . D/d . Ccoffee,
which should yield a linear relationship between Cslurry and t. Or am I missing something here?
3. Also, in your simulation of 30 coffee compounds, did you keep the surface area A and the thickness of the concentration gradient d fixed, while varying the diffusion coefficient D to reflect different extraction speeds?
4. Finally, I’d be really interested in seeing the Python code you used to generate these plots 🙂
Thanks for clarifying! And keep up the amazing work!
LikeLike
Hey thanks ! 1. Yes 2. Almost, but Ccoffee is also a function of time as the coffee particle gets depleted, so it’s only linear for a short moment. 3. Yes. 4. Send me an email through the contact form, I’ll send you the code.
LikeLike
Hello! Does this mean that for a certain brew that uses a single pour, if you split your one continuous pour into several pulse pours and wait for them to drain for each pulse you’re also over-representing those fast extracting compounds more than if you brew with a one continuous pour?
I’ve tried doing this on one of my familiar brews (from one pour to two pours with drain) and I found it to be noticeably different from the single pour.
LikeLike
This is most likely because you are extracting more with 2 pours. If you normalise extraction via grind size you can brew similar extractions/tasting cups with very different pour regimes.
LikeLiked by 1 person
Hi! I’ve made the experience, that I prefer different water compositions for immersion and percolation processes. While I prefer the classic Rao style water (alkalinity 40ppm CaCO3, total hardness 90ppm CaCO3) for percolation processes, I get subjectively better results with softer water for immersion processes (so far the best results in blind tasting I had with an alkalinity of 28ppm CaCO3 and a total hardness of 55ppm CaCO3). Last year’s WAC winner even used water with a TDS of 33ppm.
Do you see any theoretical explanation for why this might be? Is the softer water able to dissolve more of the coffee’s chemical compounds until saturated?
Thank you heaps for your great work!
LikeLike
> even if water is concentrated in a specific compound, it doesn’t prevent it from extracting other compounds efficiently.
How much can we rely on that holding true in coffee? I know in an ideal situation it’s true, but such situations are a bit hard to achieve. AFAIK, ionizing usually isn’t considered to be chemical reactions, but it certainly exists in a lot of solutions, and it affects the solubility of other compounds. A great example would be “salting out effect”, there isn’t technically chemical reaction, but …
https://en.wikipedia.org/wiki/Salting_out
LikeLike
That’s a good question, to which I don’t know the answer. It’s definitely possible that there are some effects I’m not aware of that can’t be called chemical reactions, I just don’t know enough about chemistry.
LikeLike